Book Notes
6.1 Minimum Spanning Trees
6.1.1 Prim’s Algorithm
A greedy algorithm suffices for correctness: we always add the lowest-weight edge linking a vertex in the tree to a vertex on the outside. (选取相邻最近的不在树内的点。)
prim(graph *g, int start) { int i; /* counter */ edgenode *p; /* temporary pointer */ bool intree[MAXV+1]; /* is the vertex in the tree yet? */ int distance[MAXV+1]; /* cost of adding to tree */ int v; /* current vertex to process */ int w; /* candidate next vertex */ int weight; /* edge weight */ int dist; /* best current distance from start */ for (i=1; i<=g->nvertices; i++) { intree[i] = FALSE; distance[i] = MAXINT; parent[i] = -1; } distance[start] = 0; v = start; while (intree[v] == FALSE) { intree[v] = TRUE; p = g->edges[v]; while (p != NULL) { w = p->y; weight = p->weight; if ((distance[w] > weight) && (intree[w] == FALSE)) { distance[w] = weight; parent[w] = v; } p = p->next; } v = 1; dist = MAXINT; for (i=1; i<=g->nvertices; i++) if ((intree[i] == FALSE) && (dist > distance[i])) { dist = distance[i]; v=i; } } }
6.1.2 Kruskal’s Algorithm
The algorithm repeatedly considers the lightest remaining edge and tests whether its two endpoints lie within the same connected component. (最短边)
a clever data structure calledunion-find,can support such queries in O(lgn) time. With this data structure, Kruskal’s algorithm runs in O(mlgm) time.
Implementation
kruskal(graph *g) { int i; /* counter */ set_union s; /* set union data structure */ edge_pair e[MAXV+1]; /* array of edges data structure */ bool weight_compare(); set_union_init(&s, g->nvertices); to_edge_array(g, e); /* sort edges by increasing cost */ qsort(&e,g->nedges,sizeof(edge_pair),weight_compare); for (i=0; i<(g->nedges); i++) { if (!same_component(s,e[i].x,e[i].y)) { printf("edge (%d,%d) in MST\n",e[i].x,e[i].y); union_sets(&s,e[i].x,e[i].y); } } }
6.1.3 The Union-Find Data Structure
- Find(i)– Find the root of tree containing elementi, by walking up the parent pointers until there is nowhere to go. Return the label of the root.
- Union(i,j)– Link the root of one of the trees (say
containingi)to the root of the tree containing the other
(say j) so
find(i)now equalsfind(j).
We must double the number of nodes in the tree to get an extra unit of height. How many doublings can we do before we use up allnnodes? At most, lg2ndoublings can be performed. Thus, we can do both unions and finds in O(logn), good enough for Kruskal’s algorithm. In fact, union-find can be done even faster, as discussed in Section 12.5.
Implementation
typedef struct { int p[SET_SIZE+1]; /* parent element */ int size[SET_SIZE+1]; /* number of elements in subtree i */ int n; /* number of elements in set */ } set_union; set_union_init(set_union *s, int n) { int i; /* counter */ for (i=1; i<=n; i++) { s->p[i] = i; s->size[i] = 1; } s->n = n; } int find(set_union *s, int x) { if (s->p[x] == x) return(x); else return( find(s,s->p[x]) ); } int union_sets(set_union *s, int s1, int s2) { int r1, r2; /* roots of sets */ r1 = find(s,s1); r2 = find(s,s2); if (r1 == r2) return; /* already in same set */ if (s->size[r1] >= s->size[r2]) { s->size[r1] = s->size[r1] + s->size[r2]; s->p[ r2 ] = r1; } else { s->size[r2] = s->size[r1] + s->size[r2]; s->p[ r1 ] = r2; } } bool same_component(set_union *s, int s1, int s2) { return ( find(s,s1) == find(s,s2) ); }
6.3 Shortest Paths
6.3.1 Dijkstra’s Algorithm
Given a particular start vertexs, it finds the shortest path from s to every other vertex in the graph, including your desired destination t.
Implementation
dijkstra(graph *g, int start) /* WAS prim(g,start) */ { int i; /* counter */ edgenode *p; /* temporary pointer */ bool intree[MAXV+1]; /* is the vertex in the tree yet? */ int distance[MAXV+1]; /* distance vertex is from start */ int v; /* current vertex to process */ int w; /* candidate next vertex */ int weight; /* edge weight */ int dist; /* best current distance from start */ for (i=1; i<=g->nvertices; i++) { intree[i] = FALSE; distance[i] = MAXINT; parent[i] = -1; } distance[start] = 0; v = start; while (intree[v] == FALSE) { intree[v] = TRUE; p = g->edges[v]; while (p != NULL) { w = p->y; weight = p->weight; /* CHANGED */ if (distance[w] > (distance[v]+weight)) { /* CHANGED */ distance[w] = distance[v]+weight; /* CHANGED */ parent[w] = v; } p = p->next; } v=1; dist = MAXINT; for (i=1; i<=g->nvertices; i++) if ((intree[i] == FALSE) && (dist > distance[i])) { dist = distance[i]; v=i; } } }
As implemented here, the complexity is O(n2).
Dijkstra works correctly only on graphs without negative-cost edges. The reason is that midway through the execution we may encounter an edge with weight so negative that it changes the cheapest way to get froms to some other vertex already in the tree.
6.3.2 All-Pairs Shortest Path
typedef struct { int weight[MAXV+1][MAXV+1]; /* adjacency/weight info */ int nvertices; /* number of vertices in graph */ } adjacency_matrix;
The critical issue in an adjacency matrix implementation is how we denote the edges absent from the graph. A common convention for unweighted graphs denotes graph edges by 1 and non-edges by 0. This gives exactly the wrong interpretation if the numbers denote edge weights, for the non-edges get interpreted as a free ride between vertices. Instead, we should initialize each non-edge to MAXINT.
floyd(adjacency_matrix *g) { int i,j; /* dimension counters */ int k; /* intermediate vertex counter */ int through_k; /* distance through vertex k */ for (k=1; k<=g->nvertices; k++) for (i=1; i<=g->nvertices; i++) for (j=1; j<=g->nvertices; j++) { through_k = g->weight[i][k]+g->weight[k][j]; if (through_k < g->weight[i][j]) g->weight[i][j] = through_k; } }
The Floyd-Warshall all-pairs shortest path runs in O(n3) time, which is asymptotically no better thanncalls to Dijkstra’s algorithm. However, the loops are so tight and the program so short that it runs better in practice.
6.4 War Story: Dialing for Documents
“We can get good word-use frequencies and grammatical information from a big text database called the Brown Corpus. It contains thousands of typical English sentences, each parsed according to parts of speech. But how do we factor it all in?” Harald asked.
Each possible sentence interpretation can be thought of as a path in a graph. The vertices of this graph are the complete set of possible word choices. There will be an edge from each possible choice for the ith word to each possible choice for the (i + 1)st word. The cheapest path across this graph defines the best interpretation of the sentence.
Perhaps we can count how often that pair of words occurred together in previous texts. Or we can weigh them by the part of speech of each word. Maybe nouns don’t like to be next to nouns as much as they like being next to verbs.
We can pay a cost for walking through a particular vertex that depends upon the frequency of the word. Our best sentence will be given by the shortest path across the graph.
The constraints for many pattern recognition problems can be naturally formulated as shortest path problems in graphs. In fact, there is a particularly convenient dynamic programming solution for these problems (the Viterbi algorithm). Despite the fancy name, the Viterbi algorithm is basically solving a shortest path problem on a DAG.
6.5 Network Flows and Bipartite Matching
The network flow problem asks for the maximum amount of flow which can be sent from vertices s to t in a given weighted graph G while respecting the maximum capacities of each pipe.
6.5.1 Bipartite Matching
The largest bipartite matching can be readily found using network flow. Create a source nodes that is connected to every vertex in L by an edge of weight 1. Create a sink node t and connect it to every vertex in R by an edge of weight 1. Finally, assign each edge in the bipartite graph G a weight of 1. Now, the maximum possible flow fromstotdefines the largest matching in G.
6.5.2 Computing Network Flows
The key structure is the residual flow graph, denoted as R(G, f), where Gis the input graph andfis the current flow through G.
The maximum flow fromstotalways equals the weight of the minimums-t cut. Thus, flow algorithms can be used to solve general edge and vertex connectivity problems in graphs.
Implementation
typedef struct { int v; /* neighboring vertex */ int capacity; /* capacity of edge */ int flow; /* flow through edge */ int residual; /* residual capacity of edge */ struct edgenode *next; /* next edge in list */ } edgenode; netflow(flow_graph *g, int source, int sink) { int volume; /* weight of the augmenting path */ add_residual_edges(g); initialize_search(g); bfs(g,source); volume = path_volume(g, source, sink, parent); while (volume > 0) { augment_path(g,source,sink,parent,volume); initialize_search(g); bfs(g,source); volume = path_volume(g, source, sink, parent); } } bool valid_edge(edgenode *e) { if (e->residual > 0) return (TRUE); else return(FALSE); } int path_volume(flow_graph *g, int start, int end, int parents[]) { edgenode *e; /* edge in question */ edgenode *find_edge(); if (parents[end] == -1) return(0); e = find_edge(g,parents[end],end); if (start == parents[end]) return(e->residual); else return( min(path_volume(g,start,parents[end],parents), e->residual) ); } edgenode *find_edge(flow_graph *g, int x, int y) { edgenode *p; /* temporary pointer */ p = g->edges[x]; while (p != NULL) { if (p->v == y) return(p); p = p->next; } return(NULL); } augment_path(flow_graph*g,intstart,intend,intparents[],intvolume) { edgenode *e; /* edge in question */ edgenode *find_edge(); if (start == end) return; e = find_edge(g,parents[end],end); e->flow += volume; e->residual -= volume; e = find_edge(g,end,parents[end]); e->residual += volume; augment_path(g,start,parents[end],parents,volume); }
Edmonds and Karp [EK72] proved that always selecting ashortest unweighted augmenting path guarantees that O(n3) augmentations suffice for optimization.
6.6 Design Graphs, Not Algorithms
The secret is learning to design graphs, not algorithms. We have already seen a few instances of this idea:
- The maximum spanning tree can be found by negating the edge weights of the input graph G and using aminimumspanning tree algorithm on the result. The most negative weight spanning tree will define the maximum weight tree in G.
- To solve bipartite matching, we constructed a special network flow graph such that the maximum flow corresponds to a maximum cardinality matching.
Bucketing Rectangles
Problem: “In my graphics work I need to solve the following problem. Given an arbitrary set of rectangles in the plane, how can I distribute them into a minimum number of buckets such that no subset of rectangles in any given bucket intersects another? In other words, there can not be any overlapping area between two rectangles in the same bucket.”
Solution: We formulate a graph where each vertex is a rectangle, and there is an edge if two rectangles intersect. Each bucket corresponds to anindependent set of rectangles, so there is no overlap between any two. Avertex coloringof a graph is a partition of the vertices into independent sets, so minimizing the number of colors is exactly what you want.
Names in Collision
Problem:“In porting code from UNIX to DOS, I have to shorten several hundred file names down to at most 8 characters each. I can’t just use the first eight characters from each name, because “filename1” and “filename2” would be assigned the exact same name. How can I meaningfully shorten the names while ensuring that they do not collide?”
Solution: Construct a bipartite graph with vertices corresponding to each original file namefi for 1≤i≤n, as well as a collection of acceptable shortenings for each name fi1,…,fik. Add an edge between each original and shortened name. We now seek a set of n edges that have no vertices in common, so each file name is mapped to a distinct acceptable substitute. Bipartite matching, discussed in Section 15.6 (page 498), is exactly this problem of finding an independent set of edges in a graph.
Separate the Text
Problem: “We need a way to separate the lines of text in the optical characterrecognition system that we are building. Although there is some white space between the lines, problems like noise and the tilt of the page makes it hard to find. How can we do line segmentation?
Solution: Consider the following graph formulation. Treat each pixel in the image as a vertex in the graph, with an edge between two neighboring pixels. The weight of this edge should be proportional to how dark the pixels are. A segmentation between two lines is a path in this graph from the left to right side of the page. We seek a relatively straight path that avoids as much blackness as possible. This suggests that theshortest pathin the pixel graph will likely find a good line segmentation.
Exercises
2-3
Is the path between two vertices in a minimum spanning tree necessarily a shortest path between the two vertices in the full graph? Give a proof or a counterexample.
Assume that all edges in the graph have distinct edge weights (i.e. , no pair of edges have the same weight). Is the path between a pair of vertices in a minimum spanning tree necessarily a shortest path between the two vertices in the full graph? Give a proof or a counterexample.
不必要. 如下图,若 a 是 6 的话,minimum spanning tree 不会选择 a,但 A 和 C 间的最短路径会选择 a.
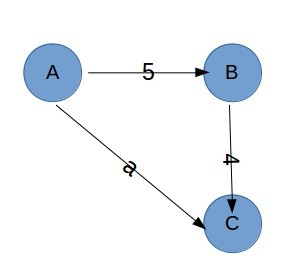
4
Can Prim’s and Kruskal’s algorithm yield different minimum spanning trees? Explain why or why not.
能.当有相同 weight 的边.
当所有边的 weight 不同时,图存在唯一的 minimum spanning trees,两者生成同样的树.
5
Does either Prim’s and Kruskal’s algorithm work if there are negative edge weights? Explain why or why not.
可以.Prim 每次选相邻最近的不在树内的点,有负 weight 的边并不影响它. 而 Kruskal 每次选最短的边,同样不受影响.
6
Suppose we are given the minimum spanning tree T of a given graph G (with n vertices and m edges) and a new edge e = (u,v) of weight w that we will add to G. Give an efficient algorithm to find the minimum spanning tree of the graph G + e. Your algorithm should run in O(n) time to receive full credit.
新添加的 e 在顶点 u 和 v 中间,原本的 MST 中 u 和 v 通过 u->a1->ai->v,把此路径的边与 e 比较,用 Prim 算法选最临近点.
7
(a) Let T be a minimum spanning tree of a weighted graph G. Construct a new graph G′ by adding a weight of k to every edge of G. Do the edges of T form a minimum spanning tree of G′? Prove the statement or give a counterexample.
(b) Let P = {s, … , t} describe a shortest weighted path between vertices s and t of a weighted graph G. Construct a new graph G′ by adding a weight of k to every edge of G. Does P describe a shortest path from s to t in G′? Prove the statement or give a counterexample.
(a)和(b)都对,并没有改变边之间的比较关系.
8
Devise and analyze an algorithm that takes a weighted graph G and finds the smallest change in the cost to a non-MST edge that would cause a change in the minimum spanning tree of G. Your algorithm must be correct and run in polynomial time.
- 遍历图的边,掠过 MST 中的边,当遇到 non-MST 的边 E(i,j).
- 利用 MST 中的 parent 遍历出顶点 i 到 j 的所有 MST 边,并得到其中最大 weight 的边 mstemax.
- 计算 E(i,j)与 mstemax 的差值.
- 遍历所有的 non-MST 的边,得到最小差值就是改变的最小值.
总共边数 m,算法复杂度 O(m2).
9
Consider the problem of finding a minimum weight connected subset T of edges from a weighted connected graph G. The weight of T is the sum of all the edge weights in T.
- Why is this problem not just the minimum spanning tree problem? Hint: think negative weight edges.
- Give an efficient algorithm to compute the minimum weight connected subset T.
MST 不能有环路,minimum weight connected subset T 可以有环路,所以如果一条负数 weight 的边,不在 MST 中,但却包含在 T 中,因为它能使 T 的总权值减小.
- 把所有负数 weight 的边加入 T 中,若剩下 1 个连通图,结束.
- 若剩下 C(>1)个连通图,对 C 个连通图使用 Kruskal,直到剩下一个连通图 T.
sort(edges); c := n; for edge in edges: if edge.weight < 0: if find(edge.firstEnd) != find(edge.secondEnd): --c; unite(edge.firstEnd, edge.secondEnd); else: if c == 1: break; if find(edge.firstEnd) != find(edge.secondEnd): unite(edge.firstEnd, edge.secondEnd); --c;
10
Let G=(V,E) be an undirected graph. A set F⊆E of edges is called a feedback-edge set if every cycle of G has at least one edge in F.
- Suppose that Gis unweighted. Design an efficient algorithm to find a minimum-size feedback-edge set.
- Suppose that Gis a weighted undirected graph with positive edge weights. Design an efficient algorithm to find a minimum-weight feedback-edge set.
- Minimum size feedback edge set: 使用 DFS,从任意点开始,遇到回归边, 把它加入结果 set 中,当 DFS 完成,结果 set 就是答案.
- minimum-weight feedback-edge set: 对所有 weight 值取反,用 Kruskal 算法,当遇到边 E 的顶点在同一个集合中,把 E 加入到结果 set 中,当 Kruskal 遍历完所有边后,结果 set 就是答案.
11
Modify Prim’s algorithm so that it runs in time O(nlogk) on a graph that has only k different edges costs.
- k 个不同的边值,使用一个 k 个元素的 min-heap,heap 的节点是相同距离的顶点链表.
- Prim 每次选择和更新顶点的距离在 min-heap 完成,做到 O(nlogk).
12
Devise an efficient data structure to handle the following operations on a weighted directed graph:
- Merge two given components.
- Locate which component contains a given vertex v.
- Retrieve a minimum edge from a given component.
使用 Union-Find 并添加 minimum edge.
typedef struct { int p[SET_SIZE+1]; /* parent element */ int size[SET_SIZE+1]; /* number of elements in subtree i */ int minedge[SET_SIZE+1]; int n; /* number of elements in set */ } set_union;
14
The single-destination shortest path problem for a directed graph seeks the shortest path from every vertex to a specified vertex v. Give an efficient algorithm to solve the single-destination shortest paths problem.
用 Floyd-Warshall 对于顶点 v 反向更新距离值.得到最终 shortest paths.
19
Let G be a weighted directed graph with n vertices and m edges, where all edges have positive weight. A directed cycle is a directed path that starts and ends at the same vertex and contains at least one edge. Give an O(n3) algorithm to find a directed cycle in G of minimum total weight. Partial credit will be given for an O(n2m) algorithm.
run Floyd Warshall on the graph min <- MAX_INT vertex <- None for each pair of vertices u,v if (dist(u,v) + dist(v,u) < min): min <- dist(u,v) + dist(v,u) pair <- (u,v) return path(u,v) + path(v,u)
20
Can we modify Dijkstra’s algorithm to solve the single-source longest path problem by changing minimum to maximum? If so, then prove your algorithm correct. If not, then provide a counterexample.
没有负 weight 的边,可以.
21
LetG=(V,E) be a weighted acyclic directed graph with possibly negative edge weights. Design a linear-time algorithm to solve the single-source shortest-path problem from a given source v.
for each vertex y in a topological ordering of G choose edge (x,y) minimizing d(s,x)+length(x,y) path(s,y) = path(s,x) + edge (x,y) d(s,y) = d(s,x) + length(x,y)
22
Let G=(V,E) be a directed weighted graph such that all the weights are positive. Let v and w be two vertices in G and k≤|V| be an integer. Design an algorithm to find the shortest path from v to w that contains exactly k edges. Note that the path need not be simple.
create the table D[V,k]; D[v,1] = 0; for i in other vertex except v: D[i,1] = MAX_INT; for m=2 to k: for every edge(i,j): D[j,m] = D[i,m-1] + D[i,j] P[i,m] = i Path = emtpy list i = w for m=k down to 1: Path.append(m); i = P[m,k] Path.append(V); Path.reverse();
23
Arbitrage is the use of discrepancies in currency-exchange rates to make a profit. For example, there may be a small window of time during which 1 U.S. dollar buys 0.75 British pounds, 1 British pound buys 2 Australian dollars, and 1 Australian dollar buys 0.70 U.S. dollars. At such a time, a smart trader can trade one U.S. dollar and end up with 0.75 × 2 × 0.7 = 1.05 U.S. dollars—a profit of 5%. Suppose that there are n currencies c1 , …, cn and an n × n table R of exchange rates, such that one unit of currency ci buys R[i,j] units of currency cj. Devise and analyze an algorithm to determine the maximum value of R[c1, ci1] · R[ci1, ci2] · · · R[cik−1, cik] · R[cik, c1]
log(a*b*c) = loga + lgob + log.所以求最长路径.
- 用 Floyd-Warshall 算法算出 i,j 的最长路径;
- 计算所有 C(1i)*C(i1)的值,得出最大值.